
Machine Learning Analysis in the Earth Systems Sciences¶
In this module, you are tasked with planning, implementing, and evaluating a machine learning solution for a real-world scenario. Given pre-configured code blocks and prepared data, you will create a problem statement, explore the data, experiment with model development, and ultimately make a recommendation on the utility of machine learning for your scenario.
Damaged weather station in western North Carolina¶
In the fall of 2024, a major hurricane devastated western North Carolina and Appalachia. This caused widespread damage, including damage to important weather observing instruments. Play the video below to learn more about the situation, and how machine learning might be a helpful tool.
Video opens in a new tab.

What is a data engineer?
Your team includes yourself, your team lead, and a data engineer. Data engineering is an emerging career that encompasses the collection, storage, and pre-processing of data in data science disciplines. You will see the type of work that the data engineer on your team does in Part 2: Data Handling.
Now you will begin the process of following the supervised machine learning model framework to address this task, starting with problem framing.
Click to enlarge
Part 1: Problem Framing¶
Based on the information provided in the video, which type of machine learning analysis is most appropriate for this scenario?
Instructions
Execute the two cells below. After executing
display_knowledgecheck(), select the corresponding button to check your understanding.
# First import the Python tools needed to display the buttons
# This cell may take a moment to complete
import ipywidgets as widgets
import matplotlib.pyplot as plt
from IPython.display import display, clear_output, HTML, IFrame
from analysis_tech import display_knowledgecheck
display_knowledgecheck()
Which type of machine learning analysis is most appropriate for this scenario?

Problem framing questions¶
As a part of the problem framing step, we must answer a series of questions to ensure we're creating the best solution for this scenario.
Does a simpler solution exist?
From the video, we know that your team has already completed a preliminary analysis that averaged values from nearby stations to Mt Mitchell. While these results showed some skill, there is room for improvement.
Can machine learning requirements be met?
The NC ECONet data provider has decades of hourly data available from several weather stations. This is sufficient for your model.
Which scientific question should be answered?
You will answer this question in Exercise 1 below.
Exercise 1
Open your Machine Learning Model Handbook to Exercise 1. Then type the scientific question to be answered for this situation.
Part 2: Data Handling¶
Click to enlarge
Recall that data handling is often the most time-consuming step of developing a machine learning model. Data handling comes in three parts:
- Locate data of interest
- Explore data
- Create a data splitting strategy
Your team's data engineer has located the data and completed the pre-processing for you already. You will continue with your own independent exploration of the data and then create a data splitting strategy.
Part 2a: Locate Data of Interest¶
You will be using other stations in the NC ECONet for this project. Below is a document that your team's data engineer has prepared for you describing the nature of the dataset that will be used to create the machine learning model.
Metadata Document for Western North Carolina Weather Station Data¶
General Information¶
Dataset Name: Western NC Weather Station Time-Series Data
Description: This dataset contains tabular time series data collected from multiple surface weather stations in Western North Carolina. The data includes atmospheric and environmental variables recorded at hourly intervals.
Date Range: January 1, 2015, to December 16, 2024
Geographic Coverage: Western North Carolina
Data Frequency: Hourly
Last Updated: Jan 1, 2025
Data Structure¶
File Format: .parquet
Number of Records: 69,760 per station per environmental variable (feature)
Columns (Features)
- observation_datetime: Date and time of observation in UTC
Columns (features) per Station (XXXX):
- XXXX_airtemp_degF (°F): Air temperature measured at 2 meters above ground level
- XXXX_windspeed_mph (mph): Average wind speed during the hour at 10 meters above ground level
- XXXX_winddgust_mph (mph): Peak wind gust during the hour at 10 meters above ground level
- XXXX_rh_percent (%): Average Relative humidity
- XXXX_precip_in (in): Total precipitation accumulated in the hour
Stations:
- BEAR (Bearwallow Mountain)
- BURN (Burnsville Tower)
- FRYI (Frying Pan Mountain)
- JEFF (Mount Jefferson Tower)
- MITC (Mount Mitchell State Park) - target station
- NCAT (North Carolina A&T University Research Farm)
- SALI (Piedmont Research Station)
- SASS (Sassafrass Mountain)
- UNCA (University of North Carolina - Asheville Weather Tower)
- WINE (Wayah Bald Mountain)
Data Quality¶
Missing Data: Missing data (aside from MITC) was filled in using seasonal values and simple interpolation.
Outlier Handling: No outlier handling was done.
Data Provenance¶
Source: North Carolina State Climate Office ECONet (Citation)
Part 2b: Explore Data¶
While your data engineer colleague prepared the data for your model and created the metadata document, you will still need to familiarize yourself with the data before you use it as input to a machine learning algorithm. In this step, you will take a closer look at the potential features for your model with a few plots.
First, let's read the data into this workspace. The data resides on a remote THREDDS Data Server, which serves data to users without the need to manually download files to a local computer. When you execute the code cell below, you will load the Python library pandas that includes all the tools for reading the data from the THREDDS Data Server and opening it in this workspace.
Instructions
Execute the cell below.
This may take a moment to complete.
# Import the pandas Python library that can interpret the data file
import pandas as pd
# Location of the data on the THREDDS data server
file_path = 'https://thredds.ucar.edu/thredds/fileServer/cybertraining/CyberTraining_NC_ECOnet_data.parquet'
# Read data into this workspace
df = pd.read_parquet(file_path)
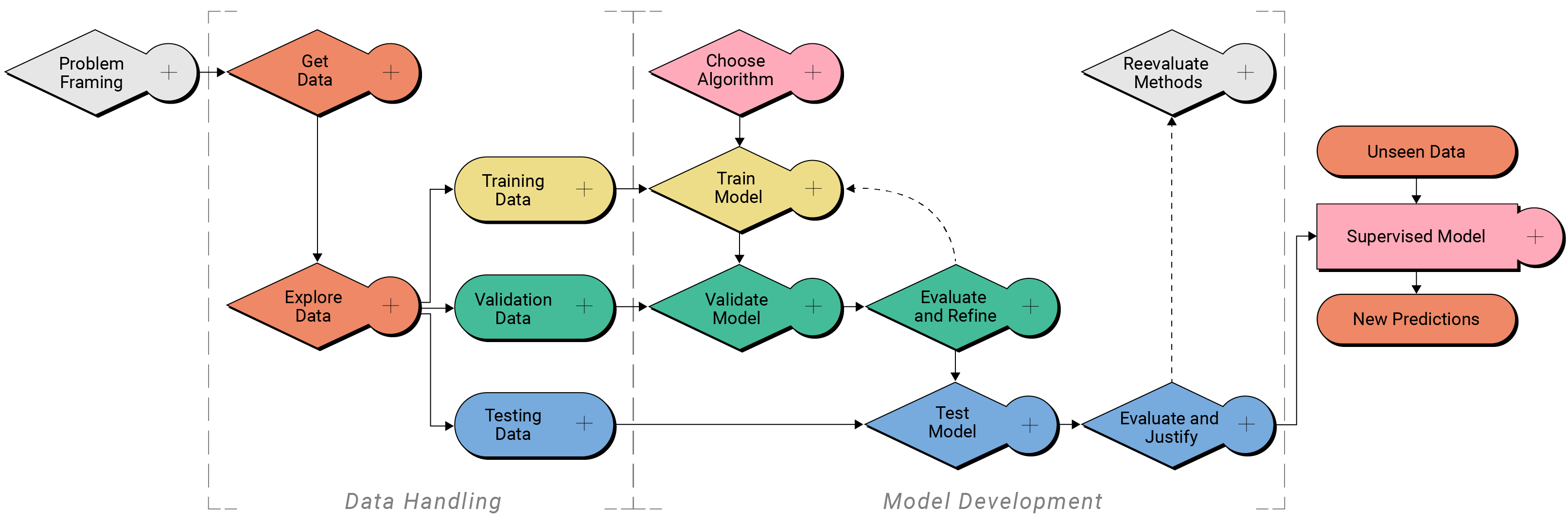
The target features (the features that we are trying to predict with the machine learning model) are temperature, relative humidity, wind speed, wind gust, and precipitation at the Mt. Mitchell station. Data from the other nearby stations are possible input features to the model.
Explore target features¶
Let's now explore just the target features at Mt. Mitchell.
Instructions
Execute the two cells below.
In the Mt. Mitchell plotting widget, select the environmental variable and plot type from the dropdowns, then select Plot to reveal the plot.
Repeat for any and all variables you want to explore to better understand the data at Mt. Mitchell.
from analysis_tech import display_mt_mitchell_weather_dashboard
display_mt_mitchell_weather_dashboard(df)
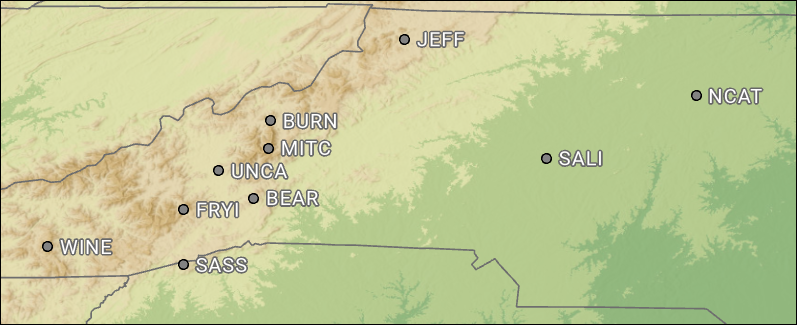
Explore input features¶
Now we will explore the input features. Below is a map of where the stations are located in relation to MITC. Western North Carolina is a part of the Appalachian Mountains in the eastern United States, so stations are located at a variety of elevations. To further explore the terrain in the area, click the image below to open an interactive 3D map.
Click to open interactive map
Instructions
Execute the two cells below.
In the Input Stations plotting widget, select the station, environmental variable, and plot type from the dropdowns. Then select Plot to reveal the plot.
Repeat for any and all variables you want to explore to better understand the data at each station.
from analysis_tech import display_input_stations_dashboard
display_input_stations_dashboard(df)
Compare stations¶
We can also plot direct comparisons of stations in our dataset by plotting data at each station in a grid of plots. In these comparison grids, the scatter plots display the observations at each station at a given time. For example, the temperature at MITC on the x-axis and the temperature at SASS on the y-axis. Stations with variables that are well-correlated will show points that are generally clustered along a line with very little spread, whereas stations with variables that are not well-correlated show considerable spread.

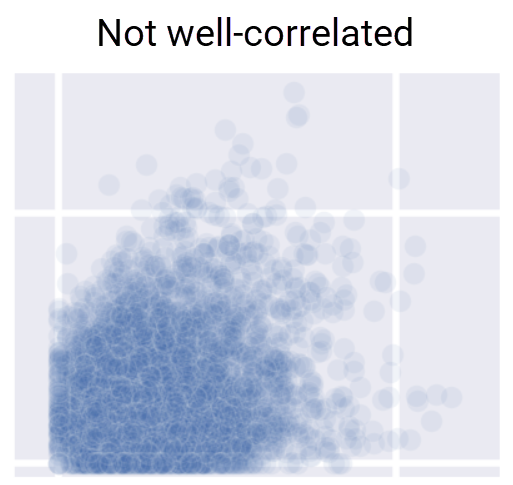
Click to enlarge
The comparison plot grid displays histograms where the x- and y-axes are the same station. These are the same histograms that you plotted previously, displaying the distribution of all values at that station.
Instructions
Execute the two cells below.
In the Comparison Plot plotting widget, select an environmental variable from the dropdown, then select Plot to reveal the plot.
Repeat for any and all variables you want to explore.
from analysis_tech import display_correlation_plot_dashboard
display_correlation_plot_dashboard()
Exercise 2b
Open your Machine Learning Model Handbook to Exercise 2b. Then describe your exploratory data analysis of any target and input features of note. Include the following:
- Do variables follow diurnal or annual patterns generally as expected?
- Do the variables have the expected ranges of values? Do any variables appear to include major outliers?
- Which stations appear to be most correlated to the variables at Mt Mitchell? Why?
- Include any important plots to illustrate your conclusions. Limit yourself to 5 plots.
To copy a plot image, hold shift, right click on the image, then select Copy.
Part 2c: Create a data splitting strategy¶
Next we create a data splitting strategy. Data splitting refers to the process of dividing data into three groups: training, validation, and testing. Each of these groups represent a part of the iterative process for machine learning model development.
- Training data is the largest subset, usually around 60-80% of the total data, and is used to initially train the model.
- Validation data is roughly 10-20% of the total data, and is used to validate the effectiveness of the training process.
- Testing data is also roughly 10-20% of the total data, and is used to test the final refined model before using it on new, unseen data.
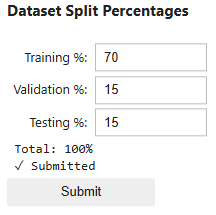
Each group should be separate to ensure no single group will bias the model. In this model, the data will be randomly split into these groups, but you decide the proportions of data for each group. Input your percentages in the blanks below, ensuring all percentages equal 100%.
Instructions
Execute the two cells below.
In the Dataset Split Percentages widget, select the proportions of the total dataset you wish to use in each group by typing in each box. Use values 0-100, ensuring that the sum of all three boxes equals 100.
Select Submit after making your selection.
from analysis_tech import create_percentage_widget
widget, get_values = create_percentage_widget()
Instructions
Execute the three cells below to execute the functions to split the data according to the percentages you submitted above.
Note: The "true test" group is the subset of times where MITC was offline, Sept 27, 2024 and onward.
# This is used to grab the values from the widget above (no need to change)
decimals = get_values()
training = decimals['training']
validation = decimals['validation']
testing = decimals['testing']
from analysis_tech import split_data_temporal
# Use the function
X_train, y_train, X_val, y_val, X_test, y_test, X_true_test, y_true_test = split_data_temporal(df,
train_pct=training,
val_pct=validation,
test_pct=testing)
Data split summary: Training period: 2017-01-01 00:00:00 to 2022-06-03 00:00:00 Training samples: 47489 (70.0% of pre-cutoff data) Validation period: 2022-06-03 01:00:00 to 2023-08-01 00:00:00 Validation samples: 10176 (15.0% of pre-cutoff data) Testing period: 2023-08-01 01:00:00 to 2024-09-28 00:00:00 Testing samples: 10176 (15.0% of pre-cutoff data) True test period: 2024-09-28 01:00:00 to 2024-12-16 23:00:00 True test samples: 1919
Exercise 2c
- In your Machine Learning Model Handbook Exercise 2c, input your data splitting strategy.
Part 3: Model Development¶
Next begins the iterative process of creating, evaluating, and refining your machine learning model. You will start with an initial model, and keep track of your subsequent trials in your Machine Learning Model Handbook.
Click to enlarge
Part 3a: Choose Algorithm¶
First, you will choose an algorithm to train. You have two options: the MultiXGBRegressor and the MultiLinearRegressor. Both have pros and cons for this task. Choose one for your initial model, but you may choose to test the other algorithm in subsequent trials.
About the Algorithms
MultiXGBRegressor (XGBoost)
- Handles a Wide Range of Data Distributions: XGBoost is capable of modeling both linear and non-linear relationships, making it suitable for data with complex, varied distributions.
- Prone to Overfitting: XGBoost can easily overfit to training data, especially when the dataset is small or noisy. This may lead to poor generalizations when making predictions on new data.
MultiLinearRegressor
- Simple and Interpretable: As a linear model, it is easy to understand and interpret within the context of the physical world, making it a great choice for finding clear relationships between features and predictions.
- Struggles with Non-Uniform Data Distributions: For datasets with non-linear patterns or skewed distributions, multiple linear regression may fail to capture the underlying patterns, leading to biased or inaccurate predictions.
Instructions
Execute the two cells below.
After executing
algorithm_selection(), select the corresponding button to select your desired algorithm.
# imports needed to run the machine learning workflow
from xgboost import XGBRegressor
import time
from sklearn.linear_model import LinearRegression
from sklearn.multioutput import MultiOutputRegressor
from analysis_tech import algorithm_selection
selected_algo = algorithm_selection()

Part 3b: Choose input features¶
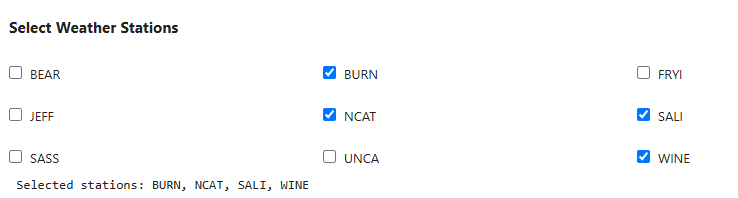
Given your data exploration, you must now choose the stations to use as input features to the algorithm you just selected. You may choose as many input stations as you'd like, however, recall that more stations does not always create a better model. Think strategically based on the evidence.
Click to open interactive map
Instructions
Execute the two cells below.
After executing
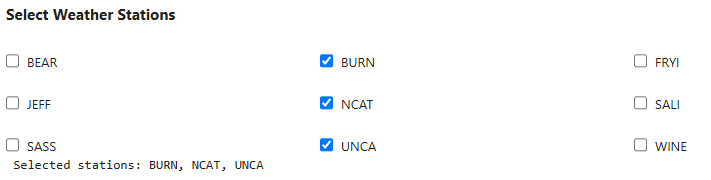
create_station_selector(), select the stations you would like to use to train your model. You may select as many or as few as you consider necessary.
from analysis_tech import create_station_selector
station_selector = create_station_selector()
Instructions
Execute the cell below to commit your station selection. The output will also be used in describing subsequent evaluation metrics.
# To get selected stations at any time:
def get_selected_stations(selector):
return [station for station, checkbox in selector.items() if checkbox.value]
selected = get_selected_stations(station_selector)
selected
['BURN', 'NCAT', 'UNCA']
This next block of code takes the full dataset and removes (filters) any stations that were not selected above. We do this for all groups (training, validation, and testing).
The "true test" group is the subset of times where MITC was offline, Sept 27, 2024 and onward.
Instructions
Execute the two cells below. In the printout display, you will see the number of features (columns) in the original dataset, and the number of features in the filtered dataset.
from analysis_tech import filter_dataframe
X_train_filtered = filter_dataframe(X_train, selected)
X_val_filtered = filter_dataframe(X_val, selected)
X_test_filtered = filter_dataframe(X_test, selected)
X_true_test_filtered = filter_dataframe(X_true_test, selected)
Original DataFrame: 47 columns Filtered DataFrame: 17 columns Original DataFrame: 47 columns Filtered DataFrame: 17 columns Original DataFrame: 47 columns Filtered DataFrame: 17 columns Original DataFrame: 47 columns Filtered DataFrame: 17 columns
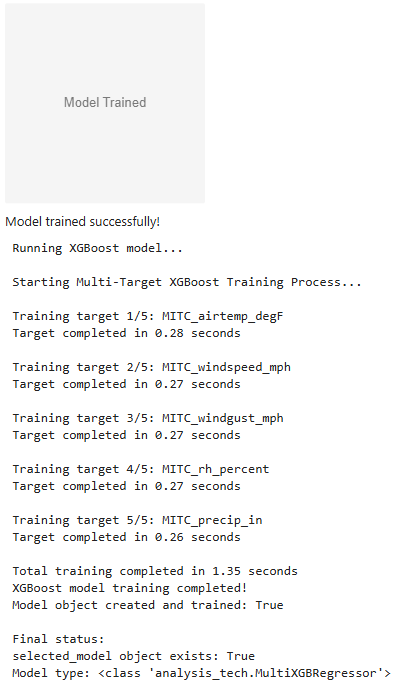
Part 3c: Train the Algorithm¶
The training process is what transforms the machine learning algorithm into a supervised machine learning model. The cells below start the training process with all the decisions you previously made.
Instructions
Execute the two cells below.
After executing
train_button(), select the Train Algorithm button to initiate the training process. A progress printout will display below the button while the process runs.
from analysis_tech import train_button
model_choice = selected_algo()
trained_model = train_button(model_choice, X_train_filtered, y_train)
Part 3d: Validate the Model¶
The validation step uses validation data to evaluate how well the training process performed. By using a separate dataset to evaluate performance, we get a better sense of how well the model can generalize to new inputs. We focus on two main evaluation metrics: Root Mean Square Error (RMSE) and R².
About the Evaluation Metrics
Root Mean Square Error (RMSE)
- A measure of how large a typical prediction error is
- Reports the typical magnitude of error in the original units (degrees, %, mph, etc)
- The closer to 0, the better the model accuracy
- Better reflects the accuracy of predictions in real-world situations
- Dependent on the range of values (scale) of the dataset, making comparisons among variables more difficult
R²
- A measure of how well the model explains the variation in the dataset
- Uses a standardized scale (0-1) for comparing models across different trials
- In some cases, R² may be negative. This means that the model made a prediction worse than the dataset average (or climatology prediction).
- The closer to 1, the better the model accuracy
- Assumes that the input data have a linear relationship
- Only measures correlation among input data, cannot distinguish good and bad predictions in the real world
Instructions
Execute the two cells below.
After executing
model_eval_MITC(), your model's validation metrics will appear below as a printout.
# Import the Python libraries that calculate the evaluation metrics
import numpy as np
from sklearn.metrics import root_mean_squared_error, r2_score
from analysis_tech import model_eval_MITC
model_eval_MITC(trained_model(), X_test_filtered, y_test)
Validation Metrics Model Type: MultiXGBRegressor Stations used (3/9): BURN, NCAT, UNCA RMSE for each target feature: MITC_airtemp_degF: 4.4934 MITC_windspeed_mph: 6.9852 MITC_windgust_mph: 8.2759 MITC_rh_percent: 22.1142 MITC_precip_in: 0.0582 R² Score for each target feature: MITC_airtemp_degF: 0.8872 MITC_windspeed_mph: 0.1141 MITC_windgust_mph: 0.3543 MITC_rh_percent: -0.2854 MITC_precip_in: 0.0829 Average R² Score: 0.23
Part 3e: Evaluate and Refine the Model¶
Examine the results of the model validation. What do each mean? Could they be improved? Review the descriptions of the evaluation metrics, then complete the next exercise.
Exercise 3e
Open your Machine Learning Model Handbook to Exercise 3e.
Paste your validation evaluation metrics in the designated box.
Then describe the results of your initial model validation. Include the following:
- Which variables have favorable evaluation metrics? Which variables don’t perform as well?
- How do you interpret these statistics in the context of the physical world?
- What changes will you make to try to improve these statistics in the next iteration?
Part 3f: Iterative Refinement Trials¶
Your first trial is complete! Now you'll create new trials to improve the evaluation metrics from the validation phase. You may complete as many trials as you like until you are satisfied with the evaluation metrics, or they no longer improve with new trials.
Instructions
Execute the code cells below, selecting your desired model configurations after executing each cell.
After each new trial, you will copy the validation metrics in your handbook document. See Exercise 3f.
You may complete as many trials in this section (3f) as you like until you are satisfied with the evaluation metrics, or they no longer improve with new trials.
New trial: Choose algorithm¶
selected_algo = algorithm_selection()

station_selector = create_station_selector()
# Execute this cell after selecting stations
selected = get_selected_stations(station_selector)
X_train_filtered = filter_dataframe(X_train, selected)
X_val_filtered = filter_dataframe(X_val, selected)
X_test_filtered = filter_dataframe(X_test, selected)
X_true_test_filtered = filter_dataframe(X_true_test, selected)
Original DataFrame: 47 columns Filtered DataFrame: 22 columns Original DataFrame: 47 columns Filtered DataFrame: 22 columns Original DataFrame: 47 columns Filtered DataFrame: 22 columns Original DataFrame: 47 columns Filtered DataFrame: 22 columns
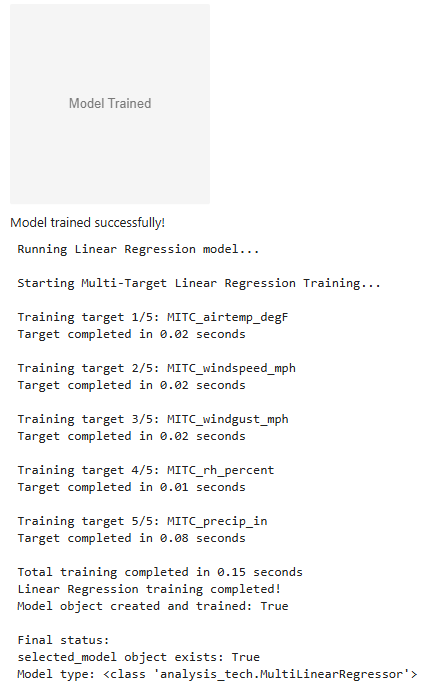
New trial: Train algorithm¶
model_choice = selected_algo()
trained_model = train_button(model_choice, X_train_filtered, y_train)
New trial: Validate model¶
model_eval_MITC(trained_model(), X_test_filtered, y_test)
Validation Metrics Model Type: MultiLinearRegressor Stations used (4/9): BURN, NCAT, SALI, WINE RMSE for each target feature: MITC_airtemp_degF: 3.6752 MITC_windspeed_mph: 6.4972 MITC_windgust_mph: 7.6509 MITC_rh_percent: 16.8714 MITC_precip_in: 0.0496 R² Score for each target feature: MITC_airtemp_degF: 0.9246 MITC_windspeed_mph: 0.2336 MITC_windgust_mph: 0.4481 MITC_rh_percent: 0.2518 MITC_precip_in: 0.3336 Average R² Score: 0.44
Exercise 3f
- In your Machine Learning Model Handbook Exercise 3f, paste the full output of each of your validation trials, one per box.
- You may complete as many trials as you like until you are satisfied with the evaluation metrics, or they no longer improve with new trials. When complete, move on to the next part below.
Part 3g: Test Model¶
Important
For testing, your model needs to be in a state with your desired algorithm and input feature stations. If you haven't already, go back and run through the cells in Part 3f with your final choices one last time. This ensures that your final testing process will be executed with your desired choices.At this point, you have a trained model with validation metrics you are satisfied with. Next, it's time to test the model on brand new data: the testing dataset. The testing process mimics how the model would be used in a real-world process in a final, unbiased way.
Testing looks very similar to validation. The model makes predictions based on the input features in the testing dataset, we calculate RMSE and R² as the testing metrics.
Instructions
Execute the cell below.
After executing
model_eval_MITC(), your model's testing metrics will appear below as a printout.
model_eval_MITC(trained_model(), X_val_filtered, y_val, eval_type='Testing')
Testing Metrics Model Type: MultiLinearRegressor Stations used (4/9): BURN, NCAT, SALI, WINE RMSE for each target feature: MITC_airtemp_degF: 3.0410 MITC_windspeed_mph: 6.7678 MITC_windgust_mph: 8.2644 MITC_rh_percent: 12.7908 MITC_precip_in: 0.0371 R² Score for each target feature: MITC_airtemp_degF: 0.9475 MITC_windspeed_mph: 0.4386 MITC_windgust_mph: 0.4357 MITC_rh_percent: 0.7173 MITC_precip_in: 0.2152 Average R² Score: 0.55
Part 3h: Evaluate and Justify¶
With your model trained, validated, and tested, you can now plot the predicted model output alongside the real data before the Mt. Mitchell station went offline. You may use this information to help you address your final model justification.
Instructions
Execute the three cells below.
The plot displays the historical and model-predicted data at Mt. Mitchell in the calendar year 2024.
import matplotlib.pyplot as plt
import matplotlib.dates as mdates
y_pred = trained_model().predict(X_true_test_filtered)
from analysis_tech import plot_weather_comparison
fig, axs = plot_weather_comparison(
df=df,
y_pred=y_pred,
transition_date=pd.Timestamp('2024-09-28')
)
plt.show()

Your final decision¶
Given all your evaluation, it's time to make a final decision on whether you believe this model provides sufficient skill for the needs of the situation. Go back and review your problem statement. Does this model deliver the results needed?
Exercise 3h
Open your Machine Learning Model Handbook to Exercise 3h.
Paste your testing evaluation metrics in the designated box.
Then make a final decision on whether this model delivers on the results needed with supporting justification. Include the following:
- Which environmental variables had the best evaluation metrics? List some physical scientific reasons why this may be the case.
- Is this model ready for use in the real world? Why or why not?
- What other possible changes could further improve this model?
Conclusion¶
Scientific research rarely yields a simple and straightforward right answer. Instead, scientists analyze evidence, compare it to known physical processes, and make informed recommendations based on data and statistics. As you learned in Machine Learning Foundations in the Earth System Sciences, machine learning is not an exact science, rather, it generates approximations from large datasets. This makes evaluating model quality complex. What one scientist considers a high-performing model may be insufficient to another. What matters most is your ability to justify your results within the context of physical science and the real-world stakes. As you continue your studies, remember that these models are not just numbers. They are representations of the physical world.
Acknowledgements¶
This work was supported by NSF Unidata under award #2319979 from the US National Science Foundation. Any opinions, findings, and conclusions or recommendations expressed in this material are those of the author(s) and do not necessarily reflect the views of the National Science Foundation.
We thank the North Carolina State Climate Office for contributing NC ECONet data and media to this project.